PostgreSQL、Cassandra、Ceph 是 RDBMS、NoSQL、Storage 的三个典型代表,我们将更多围绕它们展开数据库、存储的交流。
PostgreSQL 是一种非常复杂的对象-关系型数据库管理系统(ORDBMS),也是目前功能最强大,特性最丰富和最复杂的自由开源数据库系统。
Apache Cassandra 是一套开源分布式健值存储系统,它最初由Facebook开发,用于储存特别大的数据。
Ceph 是一个 Linux PB 级分布式文件系统,它还是具有企业级功能的统一存储解决方案。
Ceph之父Sage:Ceph要做分布式存储领域的Linux。
大数据参考路线图:
简单讲,可分为以下三种主要方式:
- 1、Hadoop 离线批处理、MapReduce任务处理;
- 2、Spark 实时流处理、RDD内存计算;
- 3、Hadoop和Spark 混合模式。
Hodoop和Spark的融合:
Spark adds in-Memory Compute for ETL, Machine Learning and Data Science Workloads to Hadoop.
Apache Hadoop 是大数据生态的事实标准。
Hortonworks 是最值得关注的 Hadoop 发行版,它拥有 Hadoop 项目最多的开发者和贡献者,100%开源。
产品形态:
- Hortonworks Data Platform (HDP)
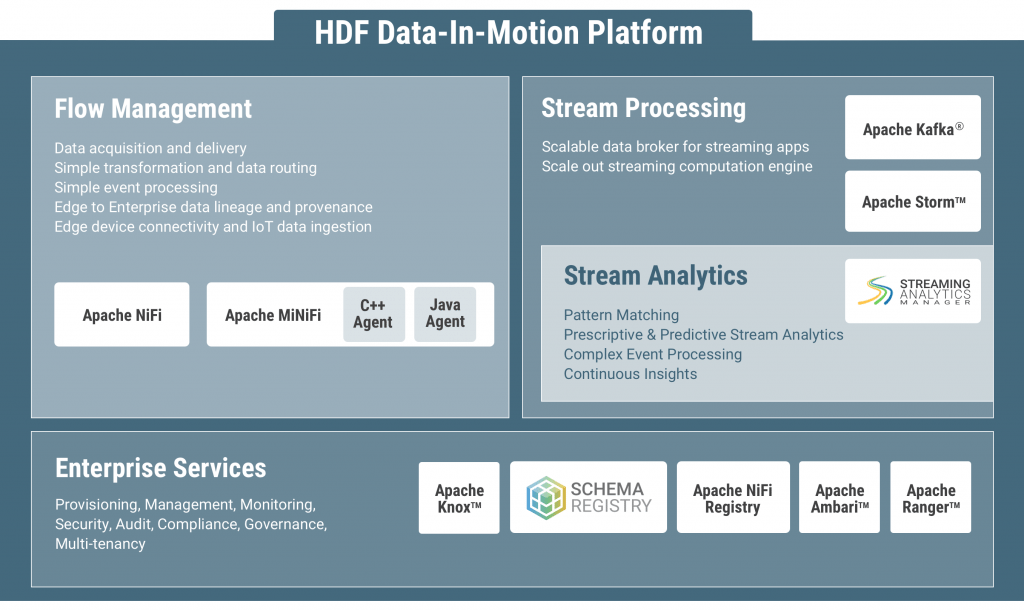
- Hortonworks DataFlow (HDF) 基于Apache NiFi,是专门用来解决数据采集,应对数据中心内外传输挑战的数据应用平台,可以从各种数据源(设备、企业应用程序、合作系统或边缘应用程序)提取数据,生成实时流数据。整合 Apache NiFi、Apache Kafka、Apache Druid
- Hortonworks Cybersecurity Platform (HCP) 位于大数据和机器学习的主要交叉点,可帮助您获得单一风险视图、自动完成威胁检测和简化运营,从而克服安全运营的人员短缺问题。HCP 由 Apache Metron 提供支持,经过精确射击,能够大规模地将多样化的流式安全数据可视化,以帮助实时检测和应对威胁。
Apache Spark:新一代大数据解决方案,常与Hadoop一起组成完整的大数据基础设施。
Spark 是用Scala和Java语言编写的一套分布式内存计算系统,它的核心抽象模型是 RDD (Resilient Distributed Dataset,弹性分布式数据集),围绕 RDD 构建了一系列分布式 API,可以直接对数据集进行分布式处理。
Alluxio是一个内存分布式文件系统,其作用是在Apache Spark或MapReduce等集群框架中实现内存级速度的跨集群文件共享。
下一代数据湖技术:Alluxio + Spark将极为重要。
可简单理解:Alluxio负责内存数据存储,而Spark负责内存数据计算。
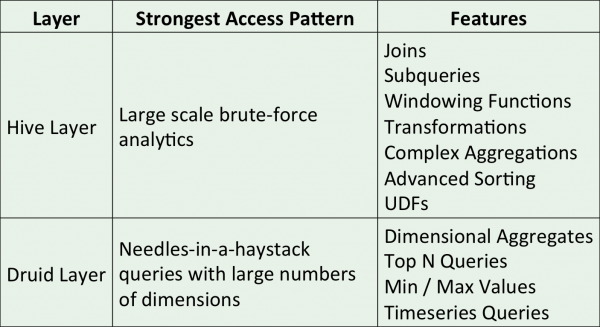
Apache Hive 是构建在 Apache Hadoop 之上的数据仓库基础设施,提供数据的汇总、查询和分析,企业可使用 Hive 构建自己的数据仓库。
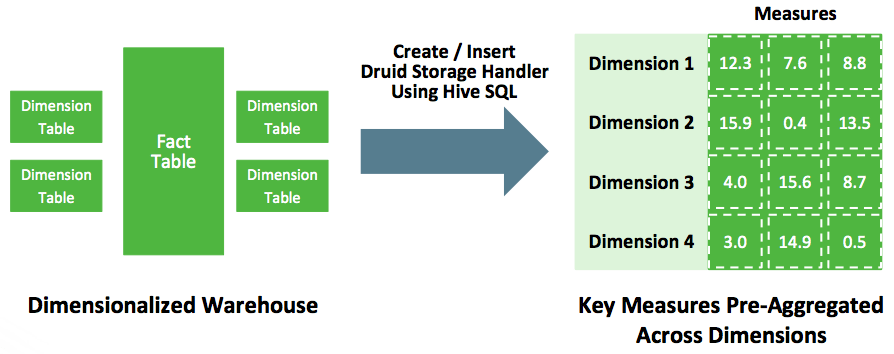
Hive 可集成 Druid 进行高速的OLAP分析,Apache Spark 也能替代 MapReduce 成为 Hive 的底层执行引擎。
Druid 是一个为OLAP设计的开源(Apache v2)事件流分析引擎。
Druid 最初主要应用于广告市场的在线数据处理领域,可以让用户基于时间序列数据做任意和互动的分析。一些关键的功能包括低延迟事件处理、快速聚合、近似和精确的计算。
Druid 的核心是一个使用专门的节点来处理每个部分的问题自定义的数据存储。实时分析基于实时管理(JVM)节点来处理,最终数据会存储在历史节点中负责老的数据。代理节点直接查询实时和历史节点,给用户一个完整的事件信息。测试表明50万事件数据能够在一秒内处理完成,并且每秒处理能力可以达到100万的峰值,Druid作为在线广告处理、网络流量和其他的活动流的理想实时处理平台。
随着Apache Hadoop生态圈的发展,SQL on Hadoop 会逐渐蚕食数据仓库市场。
基于Hadoop的OLTP/OLAP、SQL引擎、数据库存储和数据仓库解决方案:
- Apache Spark Spark on HBase & Spark on YARN
- Apache HBase
- Apache Phoenix
- Apache Hive
- Apache Kylin
- Apache Tajo
- Apache Accumulo
- Apache Trafodion
- Apache Calcite
- Apache Drill
- Apache Impala
- Apache HAWQ
- Apache Kudu
- Apache ORC
- Apache Parquet
- Apache Sqoop
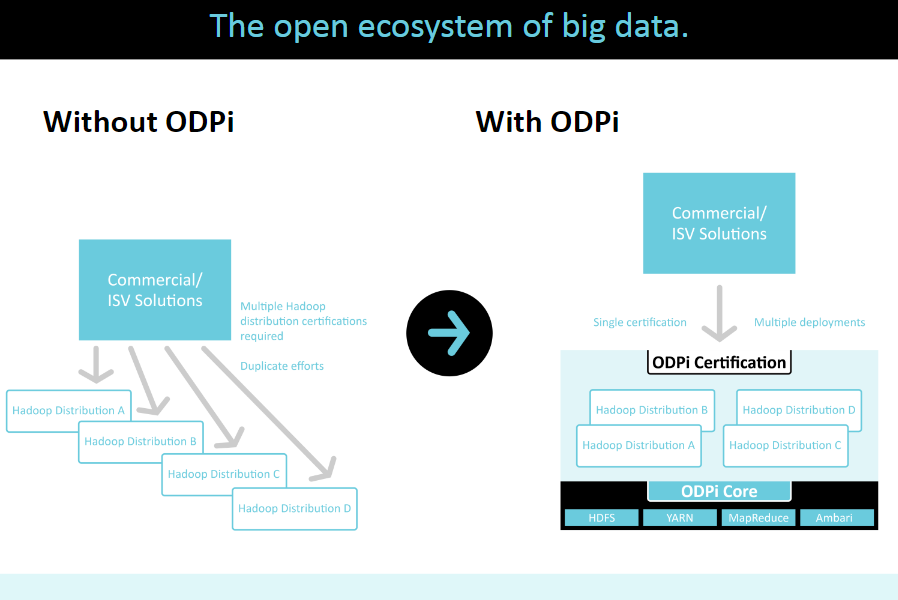
ODPi: 开放的大数据生态系统,Linux基金会发起。
ODPi认证和兼容性产品:
- Hortonworks Data Platform
- Pivotal HD
- IBM Open Platform
- Infosys Information Platform
- Stream Processing Frameworks and Products as Game Changers for the Internet of Things
- Java, Scala, and Friends: Touring the Java Bedrock of Big Data
- Securing Your Big Data Environment
- Securing the Big Data Ecosystem
- Harnessing Big Data for Application Security Intelligence
- Security Business Intelligence– Big Data for Faster Detection/Response
- MADlib: Big Data Machine Learning in PostgreSQL
- The Next Wave of SQL-on-Hadoop: Building a Virtual EDW on Native Hadoop Data
- Hive Now Sparks
- Interoperability in the Apache Hive Ecosystem



课程和课件采用CC

代码采用Apache v2
若这份教程对你有帮助,你可以通过赞助的方式鼓励我们并成为灰狐的朋友们。